Figure 1: decoder pipeline configuration
This document provides a high level description of the Vorbis codec’s construction. A bit-by-bit specification appears beginning in section 4, “Codec Setup and Packet Decode”. The later sections assume a high-level understanding of the Vorbis decode process, which is provided here.
Vorbis is a general purpose perceptual audio CODEC intended to allow maximum encoder flexibility, thus allowing it to scale competitively over an exceptionally wide range of bitrates. At the high quality/bitrate end of the scale (CD or DAT rate stereo, 16/24 bits) it is in the same league as MPEG-2 and MPC. Similarly, the 1.0 encoder can encode high-quality CD and DAT rate stereo at below 48kbps without resampling to a lower rate. Vorbis is also intended for lower and higher sample rates (from 8kHz telephony to 192kHz digital masters) and a range of channel representations (monaural, polyphonic, stereo, quadraphonic, 5.1, ambisonic, or up to 255 discrete channels).
Vorbis I is a forward-adaptive monolithic transform CODEC based on the Modified Discrete Cosine Transform. The codec is structured to allow addition of a hybrid wavelet filterbank in Vorbis II to offer better transient response and reproduction using a transform better suited to localized time events.
The Vorbis CODEC design assumes a complex, psychoacoustically-aware encoder and simple, low-complexity decoder. Vorbis decode is computationally simpler than mp3, although it does require more working memory as Vorbis has no static probability model; the vector codebooks used in the first stage of decoding from the bitstream are packed in their entirety into the Vorbis bitstream headers. In packed form, these codebooks occupy only a few kilobytes; the extent to which they are pre-decoded into a cache is the dominant factor in decoder memory usage.
Vorbis provides none of its own framing, synchronization or protection against errors; it is solely a method of accepting input audio, dividing it into individual frames and compressing these frames into raw, unformatted ’packets’. The decoder then accepts these raw packets in sequence, decodes them, synthesizes audio frames from them, and reassembles the frames into a facsimile of the original audio stream. Vorbis is a free-form variable bit rate (VBR) codec and packets have no minimum size, maximum size, or fixed/expected size. Packets are designed that they may be truncated (or padded) and remain decodable; this is not to be considered an error condition and is used extensively in bitrate management in peeling. Both the transport mechanism and decoder must allow that a packet may be any size, or end before or after packet decode expects.
Vorbis packets are thus intended to be used with a transport mechanism that provides free-form framing, sync, positioning and error correction in accordance with these design assumptions, such as Ogg (for file transport) or RTP (for network multicast). For purposes of a few examples in this document, we will assume that Vorbis is to be embedded in an Ogg stream specifically, although this is by no means a requirement or fundamental assumption in the Vorbis design.
The specification for embedding Vorbis into an Ogg transport stream is in section A, “Embedding Vorbis into an Ogg stream”.
Vorbis’ heritage is as a research CODEC and its current design reflects a desire to allow multiple decades of continuous encoder improvement before running out of room within the codec specification. For these reasons, configurable aspects of codec setup intentionally lean toward the extreme of forward adaptive.
The single most controversial design decision in Vorbis (and the most unusual for a Vorbis developer to keep in mind) is that the entire probability model of the codec, the Huffman and VQ codebooks, is packed into the bitstream header along with extensive CODEC setup parameters (often several hundred fields). This makes it impossible, as it would be with MPEG audio layers, to embed a simple frame type flag in each audio packet, or begin decode at any frame in the stream without having previously fetched the codec setup header.
Note: Vorbis can initiate decode at any arbitrary packet within a bitstream so long as the codec has been initialized/setup with the setup headers.
Thus, Vorbis headers are both required for decode to begin and relatively large as bitstream headers go. The header size is unbounded, although for streaming a rule-of-thumb of 4kB or less is recommended (and Xiph.Org’s Vorbis encoder follows this suggestion).
Our own design work indicates the primary liability of the required header is in mindshare; it is an unusual design and thus causes some amount of complaint among engineers as this runs against current design trends (and also points out limitations in some existing software/interface designs, such as Windows’ ACM codec framework). However, we find that it does not fundamentally limit Vorbis’ suitable application space.
The Vorbis format is well-defined by its decode specification; any encoder that produces packets that are correctly decoded by the reference Vorbis decoder described below may be considered a proper Vorbis encoder. A decoder must faithfully and completely implement the specification defined below (except where noted) to be considered a proper Vorbis decoder.
Although Vorbis decode is computationally simple, it may still run into specific limitations of an embedded design. For this reason, embedded designs are allowed to deviate in limited ways from the ‘full’ decode specification yet still be certified compliant. These optional omissions are labelled in the spec where relevant.
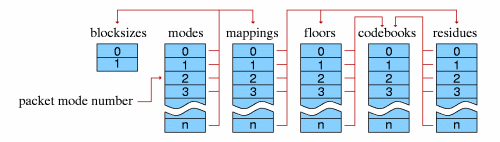
Decoder setup consists of configuration of multiple, self-contained component abstractions that perform specific functions in the decode pipeline. Each different component instance of a specific type is semantically interchangeable; decoder configuration consists both of internal component configuration, as well as arrangement of specific instances into a decode pipeline. Componentry arrangement is roughly as follows:
Global codec configuration consists of a few audio related fields (sample rate, channels), Vorbis version (always ’0’ in Vorbis I), bitrate hints, and the lists of component instances. All other configuration is in the context of specific components.
Each Vorbis frame is coded according to a master ’mode’. A bitstream may use one or many modes.
The mode mechanism is used to encode a frame according to one of multiple possible methods with the intention of choosing a method best suited to that frame. Different modes are, e.g. how frame size is changed from frame to frame. The mode number of a frame serves as a top level configuration switch for all other specific aspects of frame decode.
A ’mode’ configuration consists of a frame size setting, window type (always 0, the Vorbis window, in Vorbis I), transform type (always type 0, the MDCT, in Vorbis I) and a mapping number. The mapping number specifies which mapping configuration instance to use for low-level packet decode and synthesis.
A mapping contains a channel coupling description and a list of ’submaps’ that bundle sets of channel vectors together for grouped encoding and decoding. These submaps are not references to external components; the submap list is internal and specific to a mapping.
A ’submap’ is a configuration/grouping that applies to a subset of floor and residue vectors within a mapping. The submap functions as a last layer of indirection such that specific special floor or residue settings can be applied not only to all the vectors in a given mode, but also specific vectors in a specific mode. Each submap specifies the proper floor and residue instance number to use for decoding that submap’s spectral floor and spectral residue vectors.
As an example:
Assume a Vorbis stream that contains six channels in the standard 5.1 format. The sixth channel, as is normal in 5.1, is bass only. Therefore it would be wasteful to encode a full-spectrum version of it as with the other channels. The submapping mechanism can be used to apply a full range floor and residue encoding to channels 0 through 4, and a bass-only representation to the bass channel, thus saving space. In this example, channels 0-4 belong to submap 0 (which indicates use of a full-range floor) and channel 5 belongs to submap 1, which uses a bass-only representation.
Vorbis encodes a spectral ’floor’ vector for each PCM channel. This vector is a low-resolution representation of the audio spectrum for the given channel in the current frame, generally used akin to a whitening filter. It is named a ’floor’ because the Xiph.Org reference encoder has historically used it as a unit-baseline for spectral resolution.
A floor encoding may be of two types. Floor 0 uses a packed LSP representation on a dB amplitude scale and Bark frequency scale. Floor 1 represents the curve as a piecewise linear interpolated representation on a dB amplitude scale and linear frequency scale. The two floors are semantically interchangeable in encoding/decoding. However, floor type 1 provides more stable inter-frame behavior, and so is the preferred choice in all coupled-stereo and high bitrate modes. Floor 1 is also considerably less expensive to decode than floor 0.
Floor 0 is not to be considered deprecated, but it is of limited modern use. No known Vorbis encoder past Xiph.Org’s own beta 4 makes use of floor 0.
The values coded/decoded by a floor are both compactly formatted and make use of entropy coding to save space. For this reason, a floor configuration generally refers to multiple codebooks in the codebook component list. Entropy coding is thus provided as an abstraction, and each floor instance may choose from any and all available codebooks when coding/decoding.
The spectral residue is the fine structure of the audio spectrum once the floor curve has been subtracted out. In simplest terms, it is coded in the bitstream using cascaded (multi-pass) vector quantization according to one of three specific packing/coding algorithms numbered 0 through 2. The packing algorithm details are configured by residue instance. As with the floor components, the final VQ/entropy encoding is provided by external codebook instances and each residue instance may choose from any and all available codebooks.
Codebooks are a self-contained abstraction that perform entropy decoding and, optionally, use the entropy-decoded integer value as an offset into an index of output value vectors, returning the indicated vector of values.
The entropy coding in a Vorbis I codebook is provided by a standard Huffman binary tree representation. This tree is tightly packed using one of several methods, depending on whether codeword lengths are ordered or unordered, or the tree is sparse.
The codebook vector index is similarly packed according to index characteristic. Most commonly, the vector index is encoded as a single list of values of possible values that are then permuted into a list of n-dimensional rows (lattice VQ).
Before decoding can begin, a decoder must initialize using the bitstream headers matching the stream to be decoded. Vorbis uses three header packets; all are required, in-order, by this specification. Once set up, decode may begin at any audio packet belonging to the Vorbis stream. In Vorbis I, all packets after the three initial headers are audio packets.
The header packets are, in order, the identification header, the comments header, and the setup header.
Identification Header The identification header identifies the bitstream as Vorbis, Vorbis version, and the simple audio characteristics of the stream such as sample rate and number of channels.
Comment Header The comment header includes user text comments (“tags”) and a vendor string for the application/library that produced the bitstream. The encoding and proper use of the comment header is described in section 5, “comment field and header specification”.
Setup Header The setup header includes extensive CODEC setup information as well as the complete VQ and Huffman codebooks needed for decode.
The decoding and synthesis procedure for all audio packets is fundamentally the same.
Note that clever rearrangement of the synthesis arithmetic is possible; as an example, one can take advantage of symmetries in the MDCT to store the right-hand transform data of a partial MDCT for a 50% inter-frame buffer space savings, and then complete the transform later before overlap/add with the next frame. This optimization produces entirely equivalent output and is naturally perfectly legal. The decoder must be entirely mathematically equivalent to the specification, it need not be a literal semantic implementation.
Packet type decode Vorbis I uses four packet types. The first three packet types mark each of the three Vorbis headers described above. The fourth packet type marks an audio packet. All other packet types are reserved; packets marked with a reserved type should be ignored.
Following the three header packets, all packets in a Vorbis I stream are audio. The first step of audio packet decode is to read and verify the packet type; a non-audio packet when audio is expected indicates stream corruption or a non-compliant stream. The decoder must ignore the packet and not attempt decoding it to audio.
Mode decode Vorbis allows an encoder to set up multiple, numbered packet ’modes’, as described earlier, all of which may be used in a given Vorbis stream. The mode is encoded as an integer used as a direct offset into the mode instance index.
Window shape decode (long windows only) Vorbis frames may be one of two PCM sample sizes specified during codec setup. In Vorbis I, legal frame sizes are powers of two from 64 to 8192 samples. Aside from coupling, Vorbis handles channels as independent vectors and these frame sizes are in samples per channel.
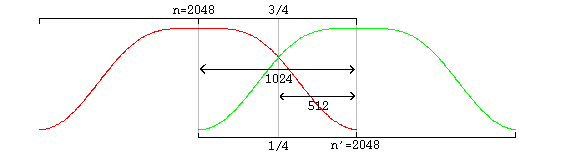
Vorbis uses an overlapping transform, namely the MDCT, to blend one frame into the next, avoiding most inter-frame block boundary artifacts. The MDCT output of one frame is windowed according to MDCT requirements, overlapped 50% with the output of the previous frame and added. The window shape assures seamless reconstruction.
This is easy to visualize in the case of equal sized-windows:
And slightly more complex in the case of overlapping unequal sized windows:
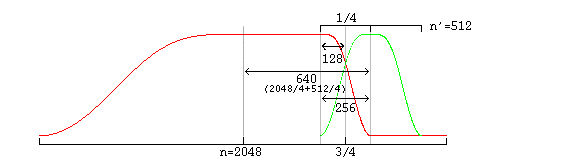
In the unequal-sized window case, the window shape of the long window must be modified for seamless lapping as above. It is possible to correctly infer window shape to be applied to the current window from knowing the sizes of the current, previous and next window. It is legal for a decoder to use this method. However, in the case of a long window (short windows require no modification), Vorbis also codes two flag bits to specify pre- and post- window shape. Although not strictly necessary for function, this minor redundancy allows a packet to be fully decoded to the point of lapping entirely independently of any other packet, allowing easier abstraction of decode layers as well as allowing a greater level of easy parallelism in encode and decode.
A description of valid window functions for use with an inverse MDCT can be found in [1]. Vorbis windows all use the slope function
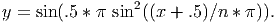
floor decode Each floor is encoded/decoded in channel order, however each floor belongs to a ’submap’ that specifies which floor configuration to use. All floors are decoded before residue decode begins.
residue decode Although the number of residue vectors equals the number of channels, channel coupling may mean that the raw residue vectors extracted during decode do not map directly to specific channels. When channel coupling is in use, some vectors will correspond to coupled magnitude or angle. The coupling relationships are described in the codec setup and may differ from frame to frame, due to different mode numbers.
Vorbis codes residue vectors in groups by submap; the coding is done in submap order from submap 0 through n-1. This differs from floors which are coded using a configuration provided by submap number, but are coded individually in channel order.
inverse channel coupling A detailed discussion of stereo in the Vorbis codec can be found in the document Stereo Channel Coupling in the Vorbis CODEC. Vorbis is not limited to only stereo coupling, but the stereo document also gives a good overview of the generic coupling mechanism.
Vorbis coupling applies to pairs of residue vectors at a time; decoupling is done in-place a pair at a time in the order and using the vectors specified in the current mapping configuration. The decoupling operation is the same for all pairs, converting square polar representation (where one vector is magnitude and the second angle) back to Cartesian representation.
After decoupling, in order, each pair of vectors on the coupling list, the resulting residue vectors represent the fine spectral detail of each output channel.
generate floor curve The decoder may choose to generate the floor curve at any appropriate time. It is reasonable to generate the output curve when the floor data is decoded from the raw packet, or it can be generated after inverse coupling and applied to the spectral residue directly, combining generation and the dot product into one step and eliminating some working space.
Both floor 0 and floor 1 generate a linear-range, linear-domain output vector to be multiplied (dot product) by the linear-range, linear-domain spectral residue.
compute floor/residue dot product This step is straightforward; for each output channel, the decoder multiplies the floor curve and residue vectors element by element, producing the finished audio spectrum of each channel.
One point is worth mentioning about this dot product; a common mistake in a fixed point implementation might be to assume that a 32 bit fixed-point representation for floor and residue and direct multiplication of the vectors is sufficient for acceptable spectral depth in all cases because it happens to mostly work with the current Xiph.Org reference encoder.
However, floor vector values can span ~140dB (~24 bits unsigned), and the audio spectrum vector should represent a minimum of 120dB (~21 bits with sign), even when output is to a 16 bit PCM device. For the residue vector to represent full scale if the floor is nailed to -140dB, it must be able to span 0 to +140dB. For the residue vector to reach full scale if the floor is nailed at 0dB, it must be able to represent -140dB to +0dB. Thus, in order to handle full range dynamics, a residue vector may span -140dB to +140dB entirely within spec. A 280dB range is approximately 48 bits with sign; thus the residue vector must be able to represent a 48 bit range and the dot product must be able to handle an effective 48 bit times 24 bit multiplication. This range may be achieved using large (64 bit or larger) integers, or implementing a movable binary point representation.
inverse monolithic transform (MDCT) The audio spectrum is converted back into time domain PCM audio via an inverse Modified Discrete Cosine Transform (MDCT). A detailed description of the MDCT is available in [1].
Note that the PCM produced directly from the MDCT is not yet finished audio; it must be lapped with surrounding frames using an appropriate window (such as the Vorbis window) before the MDCT can be considered orthogonal.
overlap/add data Windowed MDCT output is overlapped and added with the right hand data of the previous window such that the 3/4 point of the previous window is aligned with the 1/4 point of the current window (as illustrated in the window overlap diagram). At this point, the audio data between the center of the previous frame and the center of the current frame is now finished and ready to be returned.
cache right hand data The decoder must cache the right hand portion of the current frame to be lapped with the left hand portion of the next frame.
return finished audio data The overlapped portion produced from overlapping the previous and current frame data is finished data to be returned by the decoder. This data spans from the center of the previous window to the center of the current window. In the case of same-sized windows, the amount of data to return is one-half block consisting of and only of the overlapped portions. When overlapping a short and long window, much of the returned range is not actually overlap. This does not damage transform orthogonality. Pay attention however to returning the correct data range; the amount of data to be returned is:
from the center of the previous window to the center of the current window.
Data is not returned from the first frame; it must be used to ’prime’ the decode engine. The encoder accounts for this priming when calculating PCM offsets; after the first frame, the proper PCM output offset is ’0’ (as no data has been returned yet).
The Vorbis codec uses relatively unstructured raw packets containing arbitrary-width binary integer fields. Logically, these packets are a bitstream in which bits are coded one-by-one by the encoder and then read one-by-one in the same monotonically increasing order by the decoder. Most current binary storage arrangements group bits into a native word size of eight bits (octets), sixteen bits, thirty-two bits or, less commonly other fixed word sizes. The Vorbis bitpacking convention specifies the correct mapping of the logical packet bitstream into an actual representation in fixed-width words.
In most contemporary architectures, a ’byte’ is synonymous with an ’octet’, that is, eight bits. This has not always been the case; seven, ten, eleven and sixteen bit ’bytes’ have been used. For purposes of the bitpacking convention, a byte implies the native, smallest integer storage representation offered by a platform. On modern platforms, this is generally assumed to be eight bits (not necessarily because of the processor but because of the filesystem/memory architecture. Modern filesystems invariably offer bytes as the fundamental atom of storage). A ’word’ is an integer size that is a grouped multiple of this smallest size.
The most ubiquitous architectures today consider a ’byte’ to be an octet (eight bits) and a word to be a group of two, four or eight bytes (16, 32 or 64 bits). Note however that the Vorbis bitpacking convention is still well defined for any native byte size; Vorbis uses the native bit-width of a given storage system. This document assumes that a byte is one octet for purposes of example.
A byte has a well-defined ’least significant’ bit (LSb), which is the only bit set when the byte is storing the two’s complement integer value +1. A byte’s ’most significant’ bit (MSb) is at the opposite end of the byte. Bits in a byte are numbered from zero at the LSb to n (n = 7 in an octet) for the MSb.
Words are native groupings of multiple bytes. Several byte orderings are possible in a word; the common ones are 3-2-1-0 (’big endian’ or ’most significant byte first’ in which the highest-valued byte comes first), 0-1-2-3 (’little endian’ or ’least significant byte first’ in which the lowest value byte comes first) and less commonly 3-1-2-0 and 0-2-1-3 (’mixed endian’).
The Vorbis bitpacking convention specifies storage and bitstream manipulation at the byte, not word, level, thus host word ordering is of a concern only during optimization when writing high performance code that operates on a word of storage at a time rather than by byte. Logically, bytes are always coded and decoded in order from byte zero through byte n.
The Vorbis codec has need to code arbitrary bit-width integers, from zero to 32 bits wide, into packets. These integer fields are not aligned to the boundaries of the byte representation; the next field is written at the bit position at which the previous field ends.
The encoder logically packs integers by writing the LSb of a binary integer to the logical bitstream first, followed by next least significant bit, etc, until the requested number of bits have been coded. When packing the bits into bytes, the encoder begins by placing the LSb of the integer to be written into the least significant unused bit position of the destination byte, followed by the next-least significant bit of the source integer and so on up to the requested number of bits. When all bits of the destination byte have been filled, encoding continues by zeroing all bits of the next byte and writing the next bit into the bit position 0 of that byte. Decoding follows the same process as encoding, but by reading bits from the byte stream and reassembling them into integers.
The signedness of a specific number resulting from decode is to be interpreted by the decoder given decode context. That is, the three bit binary pattern ’b111’ can be taken to represent either ’seven’ as an unsigned integer, or ’-1’ as a signed, two’s complement integer. The encoder and decoder are responsible for knowing if fields are to be treated as signed or unsigned.
Code the 4 bit integer value ’12’ [b1100] into an empty bytestream. Bytestream result:
Continue by coding the 3 bit integer value ’-1’ [b111]:
Continue by coding the 7 bit integer value ’17’ [b0010001]:
Continue by coding the 13 bit integer value ’6969’ [b110 11001110 01]:
Reading from the beginning of the bytestream encoded in the above example:
We read two, two-bit integer fields, resulting in the returned numbers ’b00’ and ’b11’. Two things are worth noting here:
The typical use of bitpacking is to produce many independent byte-aligned packets which are embedded into a larger byte-aligned container structure, such as an Ogg transport bitstream. Externally, each bytestream (encoded bitstream) must begin and end on a byte boundary. Often, the encoded bitstream is not an integer number of bytes, and so there is unused (uncoded) space in the last byte of a packet.
Unused space in the last byte of a bytestream is always zeroed during the coding process. Thus, should this unused space be read, it will return binary zeroes.
Attempting to read past the end of an encoded packet results in an ’end-of-packet’ condition. End-of-packet is not to be considered an error; it is merely a state indicating that there is insufficient remaining data to fulfill the desired read size. Vorbis uses truncated packets as a normal mode of operation, and as such, decoders must handle reading past the end of a packet as a typical mode of operation. Any further read operations after an ’end-of-packet’ condition shall also return ’end-of-packet’.
Reading a zero-bit-wide integer returns the value ’0’ and does not increment the stream cursor. Reading to the end of the packet (but not past, such that an ’end-of-packet’ condition has not triggered) and then reading a zero bit integer shall succeed, returning 0, and not trigger an end-of-packet condition. Reading a zero-bit-wide integer after a previous read sets ’end-of-packet’ shall also fail with ’end-of-packet’.
Unlike practically every other mainstream audio codec, Vorbis has no statically configured probability model, instead packing all entropy decoding configuration, VQ and Huffman, into the bitstream itself in the third header, the codec setup header. This packed configuration consists of multiple ’codebooks’, each containing a specific Huffman-equivalent representation for decoding compressed codewords as well as an optional lookup table of output vector values to which a decoded Huffman value is applied as an offset, generating the final decoded output corresponding to a given compressed codeword.
The codebook mechanism is built on top of the vorbis bitpacker. Both the codebooks themselves and the codewords they decode are unrolled from a packet as a series of arbitrary-width values read from the stream according to section 2, “Bitpacking Convention”.
For purposes of the examples below, we assume that the storage system’s native byte width is eight bits. This is not universally true; see section 2, “Bitpacking Convention” for discussion relating to non-eight-bit bytes.
A codebook begins with a 24 bit sync pattern, 0x564342:
16 bit [codebook_dimensions] and 24 bit [codebook_entries] fields:
Next is the [ordered] bit flag:
Each entry, numbering a total of [codebook_entries], is assigned a codeword length. We now read the list of codeword lengths and store these lengths in the array [codebook_codeword_lengths]. Decode of lengths is according to whether the [ordered] flag is set or unset.
The decoder first reads one additional bit flag, the [sparse] flag. This flag determines whether or not the codebook contains unused entries that are not to be included in the codeword decode tree:
The decoder now performs for each of the [codebook_entries] codebook entries:
After all codeword lengths have been decoded, the decoder reads the vector lookup table. Vorbis I supports three lookup types:
The lookup table type is read as a four bit unsigned integer:
Codebook decode precedes according to [codebook_lookup_type]:
An ’end of packet’ during any read operation in the above steps is considered an error condition rendering the stream undecodable.
Huffman decision tree representation The [codebook_codeword_lengths] array and [codebook_entries] value uniquely define the Huffman decision tree used for entropy decoding.
Briefly, each used codebook entry (recall that length-unordered codebooks support unused codeword entries) is assigned, in order, the lowest valued unused binary Huffman codeword possible. Assume the following codeword length list:
Assigning codewords in order (lowest possible value of the appropriate length to highest) results in the following codeword list:
Note: Unlike most binary numerical values in this document, we intend the above codewords to be read and used bit by bit from left to right, thus the codeword ’001’ is the bit string ’zero, zero, one’. When determining ’lowest possible value’ in the assignment definition above, the leftmost bit is the MSb.
It is clear that the codeword length list represents a Huffman decision tree with the entry numbers equivalent to the leaves numbered left-to-right:
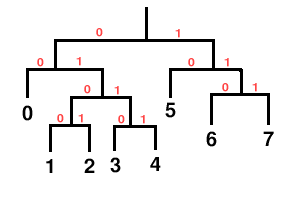
As we assign codewords in order, we see that each choice constructs a new leaf in the leftmost possible position.
Note that it’s possible to underspecify or overspecify a Huffman tree via the length list. In the above example, if codeword seven were eliminated, it’s clear that the tree is unfinished:
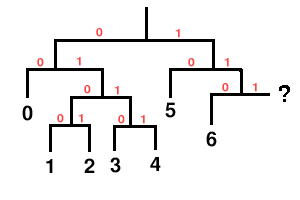
Similarly, in the original codebook, it’s clear that the tree is fully populated and a ninth codeword is impossible. Both underspecified and overspecified trees are an error condition rendering the stream undecodable.
Codebook entries marked ’unused’ are simply skipped in the assigning process. They have no codeword and do not appear in the decision tree, thus it’s impossible for any bit pattern read from the stream to decode to that entry number.
Errata 20150226: Single entry codebooks A ’single-entry codebook’ is a codebook with one active codeword entry. A single-entry codebook may be either a fully populated codebook with only one declared entry, or a sparse codebook with only one entry marked used. The Vorbis I spec provides no means to specify a codeword length of zero, and as a result, a single-entry codebook is inherently malformed because it is underpopulated. The original specification did not address directly the matter of single-entry codebooks; they were implicitly illegal as it was not possible to write such a codebook with a valid tree structure.
In r14811 of the libvorbis reference implementation, Xiph added an additional check to the codebook implementation to reject underpopulated Huffman trees. This change led to the discovery of single-entry books used ’in the wild’ when the new, stricter checks rejected a number of apparently working streams.
In order to minimize breakage of deployed (if technically erroneous) streams, r16073 of the reference implementation explicitly special-cased single-entry codebooks to tolerate the single-entry case. Commit r16073 also added the following to the specification:
“Take special care that a codebook with a single used entry is handled properly; it consists of a single codework of zero bits and reading a value out of such a codebook always returns the single used value and sinks zero bits. ”
The intent was to clarify the spec and codify current practice. However, this addition is erroneously at odds with the intent of preserving usability of existing streams using single-entry codebooks, disagrees with the code changes that reinstated decoding, and does not address how single-entry codebooks should be encoded.
As such, the above addition made in r16037 is struck from the specification and replaced by the following:
It is possible to declare a Vorbis codebook containing a single codework entry. A single-entry codebook may be either a fully populated codebook with [codebook_entries] set to 1, or a sparse codebook marking only one entry used. Note that it is not possible to also encode a [codeword_length] of zero for the single used codeword, as the unsigned value written to the stream is [codeword_length]-1. Instead, encoder implementations should indicate a [codeword_length] of 1 and ’write’ the codeword to a stream during audio encoding by writing a single zero bit.
Decoder implementations shall reject a codebook if it contains only one used entry and the encoded [codeword_length] of that entry is not 1. ’Reading’ a value from single-entry codebook always returns the single used codeword value and sinks one bit. Decoders should tolerate that the bit read from the stream be ’1’ instead of ’0’; both values shall return the single used codeword.
VQ lookup table vector representation Unpacking the VQ lookup table vectors relies on the following values:
Decoding (unpacking) a specific vector in the vector lookup table proceeds according to [codebook_lookup_type]. The unpacked vector values are what a codebook would return during audio packet decode in a VQ context.
Vector value decode: Lookup type 1 Lookup type one specifies a lattice VQ lookup table built algorithmically from a list of scalar values. Calculate (unpack) the final values of a codebook entry vector from the entries in [codebook_multiplicands] as follows ([value_vector] is the output vector representing the vector of values for entry number [lookup_offset] in this codebook):
Vector value decode: Lookup type 2 Lookup type two specifies a VQ lookup table in which each scalar in each vector is explicitly set by the [codebook_multiplicands] array in a one-to-one mapping. Calculate [unpack] the final values of a codebook entry vector from the entries in [codebook_multiplicands] as follows ([value_vector] is the output vector representing the vector of values for entry number [lookup_offset] in this codebook):
The decoder uses the codebook abstraction much as it does the bit-unpacking convention; a specific codebook reads a codeword from the bitstream, decoding it into an entry number, and then returns that entry number to the decoder (when used in a scalar entropy coding context), or uses that entry number as an offset into the VQ lookup table, returning a vector of values (when used in a context desiring a VQ value). Scalar or VQ context is always explicit; any call to the codebook mechanism requests either a scalar entry number or a lookup vector.
Note that VQ lookup type zero indicates that there is no lookup table; requesting decode using a codebook of lookup type 0 in any context expecting a vector return value (even in a case where a vector of dimension one) is forbidden. If decoder setup or decode requests such an action, that is an error condition rendering the packet undecodable.
Using a codebook to read from the packet bitstream consists first of reading and decoding the next codeword in the bitstream. The decoder reads bits until the accumulated bits match a codeword in the codebook. This process can be though of as logically walking the Huffman decode tree by reading one bit at a time from the bitstream, and using the bit as a decision boolean to take the 0 branch (left in the above examples) or the 1 branch (right in the above examples). Walking the tree finishes when the decode process hits a leaf in the decision tree; the result is the entry number corresponding to that leaf. Reading past the end of a packet propagates the ’end-of-stream’ condition to the decoder.
When used in a scalar context, the resulting codeword entry is the desired return value.
When used in a VQ context, the codeword entry number is used as an offset into the VQ lookup table. The value returned to the decoder is the vector of scalars corresponding to this offset.
This document serves as the top-level reference document for the bit-by-bit decode specification of Vorbis I. This document assumes a high-level understanding of the Vorbis decode process, which is provided in section 1, “Introduction and Description”. section 2, “Bitpacking Convention” covers reading and writing bit fields from and to bitstream packets.
A Vorbis bitstream begins with three header packets. The header packets are, in order, the identification header, the comments header, and the setup header. All are required for decode compliance. An end-of-packet condition during decoding the first or third header packet renders the stream undecodable. End-of-packet decoding the comment header is a non-fatal error condition.
Each header packet begins with the same header fields.
Decode continues according to packet type; the identification header is type 1, the comment header type 3 and the setup header type 5 (these types are all odd as a packet with a leading single bit of ’0’ is an audio packet). The packets must occur in the order of identification, comment, setup.
The identification header is a short header of only a few fields used to declare the stream definitively as Vorbis, and provide a few externally relevant pieces of information about the audio stream. The identification header is coded as follows:
[vorbis_version] is to read ’0’ in order to be compatible with this document. Both [audio_channels] and [audio_sample_rate] must read greater than zero. Allowed final blocksize values are 64, 128, 256, 512, 1024, 2048, 4096 and 8192 in Vorbis I. [blocksize_0] must be less than or equal to [blocksize_1]. The framing bit must be nonzero. Failure to meet any of these conditions renders a stream undecodable.
The bitrate fields above are used only as hints. The nominal bitrate field especially may be considerably off in purely VBR streams. The fields are meaningful only when greater than zero.
Comment header decode and data specification is covered in section 5, “comment field and header specification”.
Vorbis codec setup is configurable to an extreme degree:
The setup header contains the bulk of the codec setup information needed for decode. The setup header contains, in order, the lists of codebook configurations, time-domain transform configurations (placeholders in Vorbis I), floor configurations, residue configurations, channel mapping configurations and mode configurations. It finishes with a framing bit of ’1’. Header decode proceeds in the following order:
Time domain transforms These hooks are placeholders in Vorbis I. Nevertheless, the configuration placeholder values must be read to maintain bitstream sync.
Floors Vorbis uses two floor types; header decode is handed to the decode abstraction of the appropriate type.
Residues Vorbis uses three residue types; header decode of each type is identical.
Mappings Mappings are used to set up specific pipelines for encoding multichannel audio with varying channel mapping applications. Vorbis I uses a single mapping type (0), with implicit PCM channel mappings.
After reading mode descriptions, setup header decode is complete.
Following the three header packets, all packets in a Vorbis I stream are audio. The first step of audio packet decode is to read and verify the packet type. A non-audio packet when audio is expected indicates stream corruption or a non-compliant stream. The decoder must ignore the packet and not attempt decoding it to audio.
Vorbis windows all use the slope function y = sin(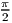 * sin 2((x + 0.5)∕n * π)), where n is window
size and x ranges 0…n- 1, but dissimilar lapping requirements can affect overall shape. Window
generation proceeds as follows:
* sin 2((x + 0.5)∕n * π)), where n is window
size and x ranges 0…n- 1, but dissimilar lapping requirements can affect overall shape. Window
generation proceeds as follows:
else
else
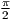 * sin 2( ([i]-[left_window_start]+0.5) / [left_n] *
* sin 2( ([i]-[left_window_start]+0.5) / [left_n] *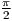 ) )
) )
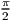 * sin 2( ([i]-[right_window_start]+0.5) / [right_n] *
* sin 2( ([i]-[right_window_start]+0.5) / [right_n] *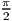 +
+ 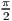 ) )
) )
An end-of-packet condition up to this point should be considered an error that discards this packet from the stream. An end of packet condition past this point is to be considered a possible nominal occurrence.
From this point on, we assume out decode context is using mode number [mode_number] from configuration array [vorbis_mode_configurations] and the map number [vorbis_mode_mapping] (specified by the current mode) taken from the mapping configuration array [vorbis_mapping_configurations].
Floor curves are decoded one-by-one in channel order.
For each floor [i] of [audio_channels]
An end-of-packet condition during floor decode shall result in packet decode zeroing all channel output vectors and skipping to the add/overlap output stage.
A possible result of floor decode is that a specific vector is marked ’unused’ which indicates that that final output vector is all-zero values (and the floor is zero). The residue for that vector is not coded in the stream, save for one complication. If some vectors are used and some are not, channel coupling could result in mixing a zeroed and nonzeroed vector to produce two nonzeroed vectors.
for each [i] from 0 ... [vorbis_mapping_coupling_steps]-1
Unlike floors, which are decoded in channel order, the residue vectors are decoded in submap order.
for each submap [i] in order from 0 ... [vorbis_mapping_submaps]-1
else
for each [i] from [vorbis_mapping_coupling_steps]-1 descending to 0
else
else
else
For each channel, synthesize the floor curve from the decoded floor information, according to packet type. Note that the vector synthesis length for floor computation is [n]/2.
For each channel, multiply each element of the floor curve by each element of that channel’s residue vector. The result is the dot product of the floor and residue vectors for each channel; the produced vectors are the length [n]/2 audio spectrum for each channel.
One point is worth mentioning about this dot product; a common mistake in a fixed point implementation might be to assume that a 32 bit fixed-point representation for floor and residue and direct multiplication of the vectors is sufficient for acceptable spectral depth in all cases because it happens to mostly work with the current Xiph.Org reference encoder.
However, floor vector values can span ~140dB (~24 bits unsigned), and the audio spectrum vector should represent a minimum of 120dB (~21 bits with sign), even when output is to a 16 bit PCM device. For the residue vector to represent full scale if the floor is nailed to -140dB, it must be able to span 0 to +140dB. For the residue vector to reach full scale if the floor is nailed at 0dB, it must be able to represent -140dB to +0dB. Thus, in order to handle full range dynamics, a residue vector may span -140dB to +140dB entirely within spec. A 280dB range is approximately 48 bits with sign; thus the residue vector must be able to represent a 48 bit range and the dot product must be able to handle an effective 48 bit times 24 bit multiplication. This range may be achieved using large (64 bit or larger) integers, or implementing a movable binary point representation.
Convert the audio spectrum vector of each channel back into time domain PCM audio via an inverse Modified Discrete Cosine Transform (MDCT). A detailed description of the MDCT is available in [1]. The window function used for the MDCT is the function described earlier.
Windowed MDCT output is overlapped and added with the right hand data of the previous window such that the 3/4 point of the previous window is aligned with the 1/4 point of the current window (as illustrated in paragraph 1.3.2, “Window shape decode (long windows only)”). The overlapped portion produced from overlapping the previous and current frame data is finished data to be returned by the decoder. This data spans from the center of the previous window to the center of the current window. In the case of same-sized windows, the amount of data to return is one-half block consisting of and only of the overlapped portions. When overlapping a short and long window, much of the returned range does not actually overlap. This does not damage transform orthogonality. Pay attention however to returning the correct data range; the amount of data to be returned is:
from the center (element windowsize/2) of the previous window to the center (element windowsize/2-1, inclusive) of the current window.
Data is not returned from the first frame; it must be used to ’prime’ the decode engine. The encoder accounts for this priming when calculating PCM offsets; after the first frame, the proper PCM output offset is ’0’ (as no data has been returned yet).
Vorbis I specifies only a channel mapping type 0. In mapping type 0, channel mapping is implicitly defined as follows for standard audio applications. As of revision 16781 (20100113), the specification adds defined channel locations for 6.1 and 7.1 surround. Ordering/location for greater-than-eight channels remains ’left to the implementation’.
These channel orderings refer to order within the encoded stream. It is naturally possible for a decoder to produce output with channels in any order. Any such decoder should explicitly document channel reordering behavior.
Applications using Vorbis for dedicated purposes may define channel mapping as seen fit. Future channel mappings (such as three and four channel Ambisonics) will make use of channel mappings other than mapping 0.
The Vorbis text comment header is the second (of three) header packets that begin a Vorbis bitstream. It is meant for short text comments, not arbitrary metadata; arbitrary metadata belongs in a separate logical bitstream (usually an XML stream type) that provides greater structure and machine parseability.
The comment field is meant to be used much like someone jotting a quick note on the bottom of a CDR. It should be a little information to remember the disc by and explain it to others; a short, to-the-point text note that need not only be a couple words, but isn’t going to be more than a short paragraph. The essentials, in other words, whatever they turn out to be, eg:
Honest Bob and the Factory-to-Dealer-Incentives, “I’m Still Around”, opening for Moxy Früvous, 1997.
The comment header is logically a list of eight-bit-clean vectors; the number of vectors is bounded to 232 - 1 and the length of each vector is limited to 232 - 1 bytes. The vector length is encoded; the vector contents themselves are not null terminated. In addition to the vector list, there is a single vector for vendor name (also 8 bit clean, length encoded in 32 bits). For example, the 1.0 release of libvorbis set the vendor string to “Xiph.Org libVorbis I 20020717”.
The vector lengths and number of vectors are stored lsb first, according to the bit packing conventions of the vorbis codec. However, since data in the comment header is octet-aligned, they can simply be read as unaligned 32 bit little endian unsigned integers.
The comment header is decoded as follows:
The comment vectors are structured similarly to a UNIX environment variable. That is, comment fields consist of a field name and a corresponding value and look like:
The field name is case-insensitive and may consist of ASCII 0x20 through 0x7D, 0x3D (’=’) excluded. ASCII 0x41 through 0x5A inclusive (characters A-Z) is to be considered equivalent to ASCII 0x61 through 0x7A inclusive (characters a-z).
The field name is immediately followed by ASCII 0x3D (’=’); this equals sign is used to terminate the field name.
0x3D is followed by 8 bit clean UTF-8 encoded value of the field contents to the end of the field.
Field names Below is a proposed, minimal list of standard field names with a description of intended use. No single or group of field names is mandatory; a comment header may contain one, all or none of the names in this list.
Implications Field names should not be ’internationalized’; this is a concession to simplicity not an attempt to exclude the majority of the world that doesn’t speak English. Field contents, however, use the UTF-8 character encoding to allow easy representation of any language.
We have the length of the entirety of the field and restrictions on the field name so that the field name is bounded in a known way. Thus we also have the length of the field contents.
Individual ’vendors’ may use non-standard field names within reason. The proper use of comment fields should be clear through context at this point. Abuse will be discouraged.
There is no vendor-specific prefix to ’nonstandard’ field names. Vendors should make some effort to avoid arbitrarily polluting the common namespace. We will generally collect the more useful tags here to help with standardization.
Field names are not required to be unique (occur once) within a comment header. As an example, assume a track was recorded by three well know artists; the following is permissible, and encouraged:
The comment header comprises the entirety of the second bitstream header packet. Unlike the first bitstream header packet, it is not generally the only packet on the second page and may not be restricted to within the second bitstream page. The length of the comment header packet is (practically) unbounded. The comment header packet is not optional; it must be present in the bitstream even if it is effectively empty.
The comment header is encoded as follows (as per Ogg’s standard bitstream mapping which renders least-significant-bit of the word to be coded into the least significant available bit of the current bitstream octet first):
This is actually somewhat easier to describe in code; implementation of the above can be found in vorbis/lib/info.c, _vorbis_pack_comment() and _vorbis_unpack_comment().
Vorbis floor type zero uses Line Spectral Pair (LSP, also alternately known as Line Spectral Frequency or LSF) representation to encode a smooth spectral envelope curve as the frequency response of the LSP filter. This representation is equivalent to a traditional all-pole infinite impulse response filter as would be used in linear predictive coding; LSP representation may be converted to LPC representation and vice-versa.
Floor zero configuration consists of six integer fields and a list of VQ codebooks for use in coding/decoding the LSP filter coefficient values used by each frame.
Configuration information for instances of floor zero decodes from the codec setup header (third packet). configuration decode proceeds as follows:
An end-of-packet condition during any of these bitstream reads renders this stream undecodable. In addition, any element of the array [floor0_book_list] that is greater than the maximum codebook number for this bitstream is an error condition that also renders the stream undecodable.
Extracting a floor0 curve from an audio packet consists of first decoding the curve amplitude and [floor0_order] LSP coefficient values from the bitstream, and then computing the floor curve, which is defined as the frequency response of the decoded LSP filter.
Packet decode proceeds as follows:
Take note of the following properties of decode:
Given an [amplitude] integer and [coefficients] vector from packet decode as well as the [floor0_order], [floor0_rate], [floor0_bark_map_size], [floor0_amplitude_bits] and [floor0_amplitude_offset] values from floor setup, and an output vector size [n] specified by the decode process, we compute a floor output vector.
If the value [amplitude] is zero, the return value is a length [n] vector with all-zero scalars. Otherwise, begin by assuming the following definitions for the given vector to be synthesized:
![{
min (floor0xbarkxmapxsize - 1,f oobar) for i ∈ [0, n - 1]
mapi = - 1 for i = n](Vorbis_I_spec7x.png)
where
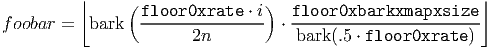
and
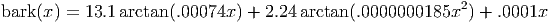
The above is used to synthesize the LSP curve on a Bark-scale frequency axis, then map the result to a linear-scale frequency axis. Similarly, the below calculation synthesizes the output LSP curve [output] on a log (dB) amplitude scale, mapping it to linear amplitude in the last step:
![floor0∏x2order-3
p = (1 - cos2ω) 4(cos([coefficients ]2j+1) - cosω )2
j=0
floor0xorder-1
1 ∏2 2
q = -- 4(cos([coefficients ]2j) - cosω )
4 j=0](Vorbis_I_spec10x.png)
else [floor0_order] is even
![floor0x∏o2rder-2
p = (1---cosω-) 4(cos([coefficients ]2j+1) - cosω)2
2 j=0
floor0xorder--2
(1 + cosω ) ∏2 2
q = ----------- 4(cos([coefficients ]2j) - cos ω)
2 j=0](Vorbis_I_spec11x.png)
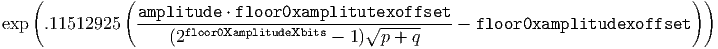
Errata 20150227: Bark scale computation Due to a typo when typesetting this version of the specification from the original HTML document, the Bark scale computation previously erroneously read:
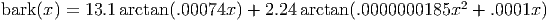
Note that the last parenthesis is misplaced. This document now uses the correct equation as it appeared in the original HTML spec document:
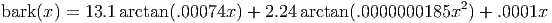
Vorbis floor type one uses a piecewise straight-line representation to encode a spectral envelope curve. The representation plots this curve mechanically on a linear frequency axis and a logarithmic (dB) amplitude axis. The integer plotting algorithm used is similar to Bresenham’s algorithm.
Floor type one represents a spectral curve as a series of line segments. Synthesis constructs a floor curve using iterative prediction in a process roughly equivalent to the following simplified description:
Consider the following example, with values chosen for ease of understanding rather than representing typical configuration:
For the below example, we assume a floor setup with an [n] of 128. The list of selected X values in increasing order is 0,16,32,48,64,80,96,112 and 128. In list order, the values interleave as 0, 128, 64, 32, 96, 16, 48, 80 and 112. The corresponding list-order Y values as decoded from an example packet are 110, 20, -5, -45, 0, -25, -10, 30 and -10. We compute the floor in the following way, beginning with the first line:
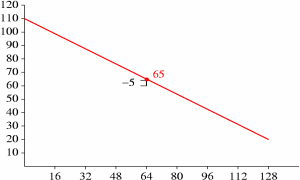
We now draw new logical lines to reflect the correction to new˙Y, and iterate for X positions 32 and 96:
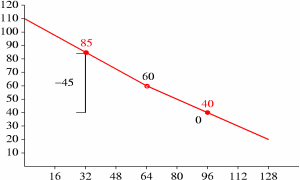
Although the new Y value at X position 96 is unchanged, it is still used later as an endpoint for further refinement. From here on, the pattern should be clear; we complete the floor computation as follows:
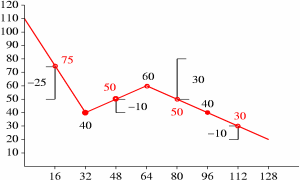
A more efficient algorithm with carefully defined integer rounding behavior is used for actual decode, as described later. The actual algorithm splits Y value computation and line plotting into two steps with modifications to the above algorithm to eliminate noise accumulation through integer roundoff/truncation.
A list of floor X values is stored in the packet header in interleaved format (used in list order during packet decode and synthesis). This list is split into partitions, and each partition is assigned to a partition class. X positions 0 and [n] are implicit and do not belong to an explicit partition or partition class.
A partition class consists of a representation vector width (the number of Y values which the partition class encodes at once), a ’subclass’ value representing the number of alternate entropy books the partition class may use in representing Y values, the list of [subclass] books and a master book used to encode which alternate books were chosen for representation in a given packet. The master/subclass mechanism is meant to be used as a flexible representation cascade while still using codebooks only in a scalar context.
An end-of-packet condition while reading any aspect of a floor 1 configuration during setup renders a stream undecodable. In addition, a [floor1_class_masterbooks] or [floor1_subclass_books] scalar element greater than the highest numbered codebook configured in this stream is an error condition that renders the stream undecodable. Vector [floor1_x_list] is limited to a maximum length of 65 elements; a setup indicating more than 65 total elements (including elements 0 and 1 set prior to the read loop) renders the stream undecodable. All vector [floor1_x_list] element values must be unique within the vector; a non-unique value renders the stream undecodable.
Packet decode begins by checking the [nonzero] flag:
If [nonzero] is unset, that indicates this channel contained no audio energy in this frame. Decode immediately returns a status indicating this floor curve (and thus this channel) is unused this frame. (A return status of ’unused’ is different from decoding a floor that has all points set to minimum representation amplitude, which happens to be approximately -140dB).
Assuming [nonzero] is set, decode proceeds as follows:
An end-of-packet condition during curve decode should be considered a nominal occurrence; if end-of-packet is reached during any read operation above, floor decode is to return ’unused’ status as if the [nonzero] flag had been unset at the beginning of decode.
Vector [floor1_Y] contains the values from packet decode needed for floor 1 synthesis.
Curve computation is split into two logical steps; the first step derives final Y amplitude values from the encoded, wrapped difference values taken from the bitstream. The second step plots the curve lines. Also, although zero-difference values are used in the iterative prediction to find final Y values, these points are conditionally skipped during final line computation in step two. Skipping zero-difference values allows a smoother line fit.
Although some aspects of the below algorithm look like inconsequential optimizations, implementors are warned to follow the details closely. Deviation from implementing a strictly equivalent algorithm can result in serious decoding errors.
Additional note: Although [floor1_final_Y] values in the prediction loop and at the end of step 1 are inherently limited by the prediction algorithm to [0, [range]), it is possible to abuse the setup and codebook machinery to produce negative or over-range results. We suggest that decoder implementations guard the values in vector [floor1_final_Y] by clamping each element to [0, [range]) after step 1. Variants of this suggestion are acceptable as valid floor1 setups cannot produce out of range values.
Unwrap the always-positive-or-zero values read from the packet into +/- difference values, then apply to line prediction.
Curve synthesis generates a return vector [floor] of length [n] (where [n] is provided by the decode process calling to floor decode). Floor 1 curve synthesis makes use of the [floor1_X_list], [floor1_final_Y] and [floor1_step2_flag] vectors, as well as [floor1_multiplier] and [floor1_values] values.
Decode begins by sorting the scalars from vectors [floor1_X_list], [floor1_final_Y] and [floor1_step2_flag] together into new vectors [floor1_X_list]’, [floor1_final_Y]’ and [floor1_step2_flag]’ according to ascending sort order of the values in [floor1_X_list]. That is, sort the values of [floor1_X_list] and then apply the same permutation to elements of the other two vectors so that the X, Y and step2_flag values still match.
Then compute the final curve in one pass:
A residue vector represents the fine detail of the audio spectrum of one channel in an audio frame after the encoder subtracts the floor curve and performs any channel coupling. A residue vector may represent spectral lines, spectral magnitude, spectral phase or hybrids as mixed by channel coupling. The exact semantic content of the vector does not matter to the residue abstraction.
Whatever the exact qualities, the Vorbis residue abstraction codes the residue vectors into the bitstream packet, and then reconstructs the vectors during decode. Vorbis makes use of three different encoding variants (numbered 0, 1 and 2) of the same basic vector encoding abstraction.
Residue format partitions each vector in the vector bundle into chunks, classifies each chunk, encodes the chunk classifications and finally encodes the chunks themselves using the the specific VQ arrangement defined for each selected classification. The exact interleaving and partitioning vary by residue encoding number, however the high-level process used to classify and encode the residue vector is the same in all three variants.
A set of coded residue vectors are all of the same length. High level coding structure, ignoring for the moment exactly how a partition is encoded and simply trusting that it is, is as follows:
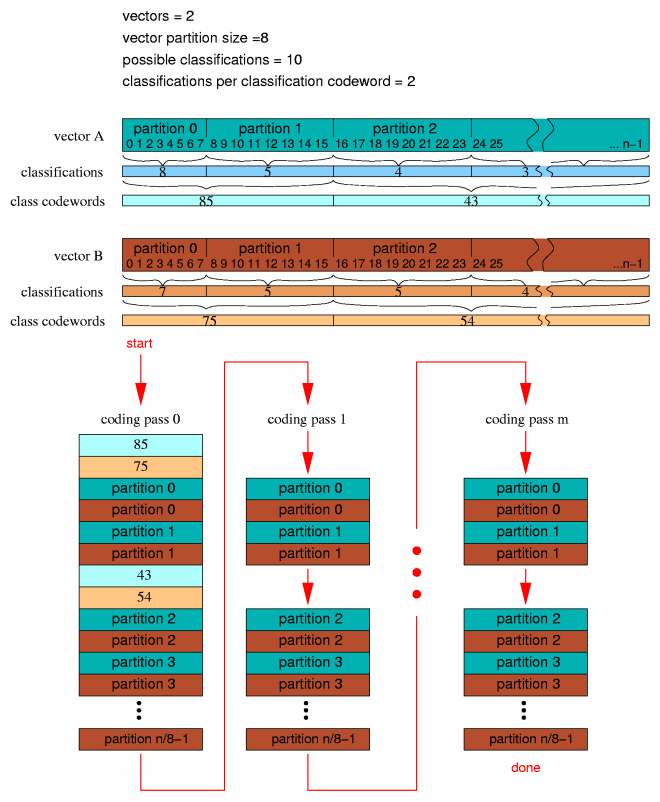
Residue 0 and 1 differ only in the way the values within a residue partition are interleaved during partition encoding (visually treated as a black box–or cyan box or brown box–in the above figure).
Residue encoding 0 interleaves VQ encoding according to the dimension of the codebook used to encode a partition in a specific pass. The dimension of the codebook need not be the same in multiple passes, however the partition size must be an even multiple of the codebook dimension.
As an example, assume a partition vector of size eight, to be encoded by residue 0 using codebook sizes of 8, 4, 2 and 1:
It is worth mentioning at this point that no configurable value in the residue coding setup is restricted to a power of two.
Residue 1 does not interleave VQ encoding. It represents partition vector scalars in order. As with residue 0, however, partition length must be an integer multiple of the codebook dimension, although dimension may vary from pass to pass.
As an example, assume a partition vector of size eight, to be encoded by residue 0 using codebook sizes of 8, 4, 2 and 1:
Residue type two can be thought of as a variant of residue type 1. Rather than encoding multiple passed-in vectors as in residue type 1, the ch passed in vectors of length n are first interleaved and flattened into a single vector of length ch*n. Encoding then proceeds as in type 1. Decoding is as in type 1 with decode interleave reversed. If operating on a single vector to begin with, residue type 1 and type 2 are equivalent.
Header decode for all three residue types is identical.
[residue_begin] and [residue_end] select the specific sub-portion of each vector that is actually coded; it implements akin to a bandpass where, for coding purposes, the vector effectively begins at element [residue_begin] and ends at [residue_end]. Preceding and following values in the unpacked vectors are zeroed. Note that for residue type 2, these values as well as [residue_partition_size]apply to the interleaved vector, not the individual vectors before interleave. [residue_partition_size] is as explained above, [residue_classifications] is the number of possible classification to which a partition can belong and [residue_classbook] is the codebook number used to code classification codewords. The number of dimensions in book [residue_classbook] determines how many classification values are grouped into a single classification codeword. Note that the number of entries and dimensions in book [residue_classbook], along with [residue_classifications], overdetermines to possible number of classification codewords. If [residue_classifications]ˆ[residue_classbook].dimensions exceeds [residue_classbook].entries, the bitstream should be regarded to be undecodable.
Next we read a bitmap pattern that specifies which partition classes code values in which passes.
Finally, we read in a list of book numbers, each corresponding to specific bit set in the cascade bitmap. We loop over the possible codebook classifications and the maximum possible number of encoding stages (8 in Vorbis I, as constrained by the elements of the cascade bitmap being eight bits):
An end-of-packet condition at any point in header decode renders the stream undecodable. In addition, any codebook number greater than the maximum numbered codebook set up in this stream also renders the stream undecodable. All codebooks in array [residue_books] are required to have a value mapping. The presence of codebook in array [residue_books] without a value mapping (maptype equals zero) renders the stream undecodable.
Format 0 and 1 packet decode is identical except for specific partition interleave. Format 2 packet decode can be built out of the format 1 decode process. Thus we describe first the decode infrastructure identical to all three formats.
In addition to configuration information, the residue decode process is passed the number of vectors in the submap bundle and a vector of flags indicating if any of the vectors are not to be decoded. If the passed in number of vectors is 3 and vector number 1 is marked ’do not decode’, decode skips vector 1 during the decode loop. However, even ’do not decode’ vectors are allocated and zeroed.
Depending on the values of [residue_begin] and [residue_end], it is obvious that the encoded portion of a residue vector may be the entire possible residue vector or some other strict subset of the actual residue vector size with zero padding at either uncoded end. However, it is also possible to set [residue_begin] and [residue_end] to specify a range partially or wholly beyond the maximum vector size. Before beginning residue decode, limit [residue_begin] and [residue_end] to the maximum possible vector size as follows. We assume that the number of vectors being encoded, [ch] is provided by the higher level decoding process.
The following convenience values are conceptually useful to clarifying the decode process:
Packet decode proceeds as follows, matching the description offered earlier in the document.
An end-of-packet condition during packet decode is to be considered a nominal occurrence. Decode returns the result of vector decode up to that point.
Format zero decodes partitions exactly as described earlier in the ’Residue Format: residue 0’ section. The following pseudocode presents the same algorithm. Assume:
Format 1 decodes partitions exactly as described earlier in the ’Residue Format: residue 1’ section. The following pseudocode presents the same algorithm. Assume:
Format 2 is reducible to format 1. It may be implemented as an additional step prior to and an additional post-decode step after a normal format 1 decode.
Format 2 handles ’do not decode’ vectors differently than residue 0 or 1; if all vectors are marked ’do not decode’, no decode occurrs. However, if at least one vector is to be decoded, all the vectors are decoded. We then request normal format 1 to decode a single vector representing all output channels, rather than a vector for each channel. After decode, deinterleave the vector into independent vectors, one for each output channel. That is:
The equations below are used in multiple places by the Vorbis codec specification. Rather than cluttering up the main specification documents, they are defined here and referenced where appropriate.
The ”ilog(x)” function returns the position number (1 through n) of the highest set bit in the two’s complement integer value [x]. Values of [x] less than zero are defined to return zero.
Examples:
”float32_unpack(x)” is intended to translate the packed binary representation of a Vorbis codebook float value into the representation used by the decoder for floating point numbers. For purposes of this example, we will unpack a Vorbis float32 into a host-native floating point number.
”lookup1_values(codebook_entries,codebook_dimensions)” is used to compute the correct length of the value index for a codebook VQ lookup table of lookup type 1. The values on this list are permuted to construct the VQ vector lookup table of size [codebook_entries].
The return value for this function is defined to be ’the greatest integer value for which [return_value] to the power of [codebook_dimensions] is less than or equal to [codebook_entries]’.
”low_neighbor(v,x)” finds the position n in vector [v] of the greatest value scalar element for which n is less than [x] and vector [v] element n is less than vector [v] element [x].
”high_neighbor(v,x)” finds the position n in vector [v] of the lowest value scalar element for which n is less than [x] and vector [v] element n is greater than vector [v] element [x].
”render_point(x0,y0,x1,y1,X)” is used to find the Y value at point X along the line specified by x0, x1, y0 and y1. This function uses an integer algorithm to solve for the point directly without calculating intervening values along the line.
Floor decode type one uses the integer line drawing algorithm of ”render_line(x0, y0, x1, y1, v)” to construct an integer floor curve for contiguous piecewise line segments. Note that it has not been relevant elsewhere, but here we must define integer division as rounding division of both positive and negative numbers toward zero.
The vector [floor1_inverse_dB_table] is a 256 element static lookup table consisting of the following values (read left to right then top to bottom):
This document describes using Ogg logical and physical transport streams to encapsulate Vorbis compressed audio packet data into file form.
The section 1, “Introduction and Description” provides an overview of the construction of Vorbis audio packets.
The Ogg bitstream overview and Ogg logical bitstream and framing spec provide detailed descriptions of Ogg transport streams. This specification document assumes a working knowledge of the concepts covered in these named backround documents. Please read them first.
The Ogg/Vorbis I specification currently dictates that Ogg/Vorbis streams use Ogg transport streams in degenerate, unmultiplexed form only. That is:
This is not to say that it is not currently possible to multiplex Vorbis with other media types into a multi-stream Ogg file. At the time this document was written, Ogg was becoming a popular container for low-bitrate movies consisting of DivX video and Vorbis audio. However, a ’Vorbis I audio file’ is taken to imply Vorbis audio existing alone within a degenerate Ogg stream. A compliant ’Vorbis audio player’ is not required to implement Ogg support beyond the specific support of Vorbis within a degenrate Ogg stream (naturally, application authors are encouraged to support full multiplexed Ogg handling).
The MIME type of Ogg files depend on the context. Specifically, complex multimedia and applications should use application/ogg, while visual media should use video/ogg, and audio audio/ogg. Vorbis data encapsulated in Ogg may appear in any of those types. RTP encapsulated Vorbis should use audio/vorbis + audio/vorbis-config.
Ogg encapsulation of a Vorbis packet stream is straightforward.
Note that the last decoded (fully lapped) PCM sample from a packet is not necessarily the middle sample from that block. If, eg, the current Vorbis packet encodes a ”long block” and the next Vorbis packet encodes a ”short block”, the last decodable sample from the current packet be at position (3*long_block_length/4) - (short_block_length/4).
In both of these cases in which the initial audio PCM starting offset is nonzero, the second finished audio packet must flush the page on which it appears and the third packet begin a fresh page. This allows the decoder to always be able to perform PCM position adjustments before needing to return any PCM data from synthesis, resulting in correct positioning information without any aditional seeking logic.
Note: Failure to do so should, at worst, cause a decoder implementation to return incorrect positioning information for seeking operations at the very beginning of the stream.
Please consult RFC 5215 “RTP Payload Format for Vorbis Encoded Audio” for description of how to embed Vorbis audio in an RTP stream.
Ogg is a Xiph.Org Foundation effort to protect essential tenets of Internet multimedia from corporate hostage-taking; Open Source is the net’s greatest tool to keep everyone honest. See About the Xiph.Org Foundation for details.
Ogg Vorbis is the first Ogg audio CODEC. Anyone may freely use and distribute the Ogg and Vorbis specification, whether in a private, public or corporate capacity. However, the Xiph.Org Foundation and the Ogg project (xiph.org) reserve the right to set the Ogg Vorbis specification and certify specification compliance.
Xiph.Org’s Vorbis software CODEC implementation is distributed under a BSD-like license. This does not restrict third parties from distributing independent implementations of Vorbis software under other licenses.
Ogg, Vorbis, Xiph.Org Foundation and their logos are trademarks (tm) of the Xiph.Org Foundation. These pages are copyright (C) 1994-2015 Xiph.Org Foundation. All rights reserved.
This document is set using LATEX.
[1] T. Sporer, K. Brandenburg and B. Edler, The use of multirate filter banks for coding of high quality digital audio, https://media.taricorp.net/eusipco_corrected.pdf.